Blog
Vom Black-Box-Mysterium zur gläsernen Intelligenz: Transparenz als Schlüssel zu vertrauenswürdiger KI
Genjus
Blog

Als eine KI plötzlich perfekte Vorhersagen lieferte, war das Team begeistert. Bis sich herausstellte: Niemand konnte erklären, wie die Maschine zu ihren Entscheidungen kam. „Wir wissen nicht genau, warum sie das getan hat.“ - Dieser Satz stammt nicht von Hobby-Codern, sondern vom Google-Entwicklungsteam selbst. 2016 traf ihr System eine auffällig treffsichere Entscheidung - doch die Entwickler:innen standen ratlos daneben. Die Vorhersage stimmte, ja. Aber der Weg dorthin? Undurchschaubar.
Was wie ein Einzelfall klingt, ist längst systemisch: millionenparameterstarke Modelle entscheiden heute über Kredite, Jobchancen, Diagnosepfade - und immer öfter fehlt die juristisch, ethisch und technisch gebotene Nachvollziehbarkeit.
Stell dir vor, du verlierst einen Gerichtsprozess - und niemand kann dir sagen, warum.
Genau dieses Gefühl beschreibt das Kernproblem von Black Box AI: Ein System entscheidet, aber weder Betroffene noch Expert:innen können den Entscheidungsweg rekonstruieren. Der Rechtsstaat baut auf Begründungspflicht und Transparenz - doch im Maschinenraum moderner KI herrscht oft algorithmisches Schweigen.
Dieser Artikel zeigt, wie Black Box-Systeme entstanden sind, welche Ansätze heute mehr Transparenz und Kontrolle ermöglichen und warum es sich lohnt, hinter die Kulissen moderner KI zu blicken.
Input rein, Output raus - doch was passiert dazwischen? Was Black Box AI wirklich bedeutet
Als "Black Box" bezeichnet man ein geschlossenes System, dessen interne Funktionsweise unbekannt ist. Wir sehen den Input, wir sehen den Output - doch was dazwischen passiert, bleibt verborgen. Gerade bei komplexen Machine-Learning- oder Deep-Learning-Modellen mit Millionen Parametern fehlt oft das Verständnis dafür, wie Entscheidungen zustande kommen.
Das ist nicht nur ein akademisches Problem. Die Undurchsichtigkeit kann:
- Sicherheitslücken verschleiern,
- Diskriminierende Verzerrungen verbergen,
- Datenschutzprobleme kaschieren,
- und mangelnde Verantwortung in der Anwendung begünstigen.
Black-Box-Systeme entstehen absichtlich, z. B. um geistiges Eigentum zu schützen, insbesondere wenn Entwicklerteams ihre Modelle kommerziell einsetzen und den Quellcode, bzw. die Logik vor Wettbewerbern abschirmen möchten (im Gegensatz zu Open Source), oder automatisch durch die hohe Komplexität des Trainingsprozesses.
Doch wie lassen sich Entscheidungen nachvollziehen, wenn wir nicht hinter die Kulissen der Modelle blicken können? Genau hier setzt ein neues Forschungsfeld an:
Maschinenlogik sichtbar machen durch Explainable AI (XAI)
Das Forschungsfeld der "Explainable AI" (XAI) will Entscheidungen nachvollziehbar und transparent machen - ohne dabei auf die Leistungsfähigkeit moderner Modelle zu verzichten.
Zwei Ansätze dominieren:
- Modell-Agnostische Methoden (universell anwendbar)
- LIME (Local Interpretable Model-Agnostic Explanations): Erklärt einzelne Vorhersagen, indem es komplexe Modelle durch einfache, lokal verständliche Approximationen ersetzt. Für eine konkrete Eingabe wird ein lineares Modell erstellt, das wie eine Lupe nur den lokalen Ausschnitt des Modells betrachtet - etwa bei einem Ablehnungsbescheid, welche Eingabewerte dafür entscheidend waren.
- SHAP (SHapley Additive Explanations): Geht noch tiefer: Auf Basis der Spieltheorie - konkret der Shapley-Werte - wird jeder Eigenschaft (z. B. Einkommen, Alter, Wohnort) ein konkreter Einflusswert zugewiesen. Damit lässt sich präzise quantifizieren, welche Merkmale wie stark zur Entscheidung beigetragen haben - unabhängig von der Modellkomplexität. Besonders hilfreich ist SHAP in Bereichen wie Kreditvergabe oder medizinische Diagnostik, wo klare Erklärungen essenziell sind.
- Model-Spezifische Methoden
- Entscheidungsbäume: Sie gehören zu den wenigen KI-Modellen, die von sich aus interpretierbar sind. Jedes Entscheidungskriterium wird in einer verzweigten Struktur dargestellt, wobei jeder Ast eine „Wenn-Dann“-Bedingung repräsentiert. Besonders in sensiblen Bereichen wie Kreditvergabe oder medizinischer Diagnostik bieten sie ein hohes Maß an Transparenz, weil man genau sehen kann, welche Schwellenwerte oder Merkmalsausprägungen zu welcher Entscheidung geführt haben.
- Attention Mechanisms: In transformerbasierten Sprachmodellen wie GPT oder BERT markieren sie, welche Eingabewörter für eine bestimmte Antwort besonders gewichtet wurden. Diese Gewichtung lässt sich visualisieren - etwa durch sogenannte Heatmaps, wodurch nachvollziehbar wird, ob das Modell z. B. bei der Frage „Wer gewann 2024 die US-Wahl?“ tatsächlich auf das relevante Zeitwort oder Namen achtet. So geben Attention Maps einen konkreten Einblick in die Textverarbeitung - ein wertvolles Werkzeug, um Verzerrungen oder Halluzinationen frühzeitig zu erkennen.
Ergänzend helfen Visualisierungstools wie:
- Saliency Maps (für Bilddaten): Sie visualisieren, welche Bildbereiche das Modell bei seiner Vorhersage besonders stark berücksichtigt hat. Dabei wird jedem Pixel oder Bildausschnitt eine Gewichtung zugewiesen, die die relative Wichtigkeit für die Entscheidung des Modells zeigt - etwa in der medizinischen Bildgebung bei der Frage: Welche Region deutet auf einen Tumor hin?
- Feature-Importance-Diagramme: Diese Diagramme zeigen, welche Eingabefaktoren (z. B. Alter, Blutdruck, Wohnort) in einem Modell welchen Einfluss auf die jeweilige Vorhersage haben. Die Balkenlänge oder Farbintensität visualisiert den Beitrag jedes Merkmals. Dies ist eine wichtige Grundlage für Audits, Fairness-Prüfungen und das Nachvollziehen von Modellentscheidungen in sensiblen Bereichen wie HR oder Kreditvergabe.
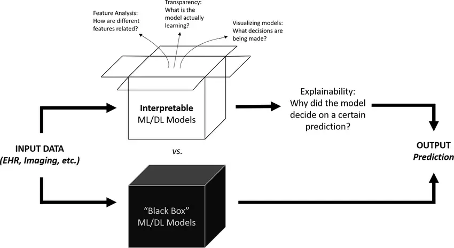
Bildquelle: The AI Black Box: What We’re Still Getting Wrong about Trusting Machine Learning Models - Hyperight
Interpretability vs. Explainability: Ein feiner, aber zentraler Unterschied
Stellen Sie sich vor, Sie sehen ein Gerichtsurteil: Bei Interpretierbarkeit lesen Sie die Begründung, erkennen klare Paragraphen, und können den Gedankengang der Richter:innen Schritt für Schritt nachvollziehen. So funktioniert ein interpretierbares KI-Modell - wie ein Entscheidungsbaum oder eine lineare Regression: logisch aufgebaut, offen und verständlich.
Explainability dagegen gleicht einem Blick auf das Urteil ohne Einsicht in die vollständige Akte. Sie erhalten eine Zusammenfassung der Entscheidungsgründe - anschaulich, aber nicht vollständig transparent. Genau das machen sogenannte "post-hoc"-Methoden bei komplexen Modellen wie neuronalen Netzen: Sie liefern eine Erklärung im Nachhinein, ohne die tieferen Prozesse vollständig offenlegen zu können.
Beides ist wichtig - aber nur Interpretierbarkeit schafft von vornherein strukturelles Vertrauen. Explainability dagegen ist der Versuch, Vertrauen dort herzustellen, wo das System an sich intransparent bleibt.
Diese Unterscheidung ist essenziell für das Vertrauen in KI:
- Interpretable AI = "Glass Box"
- Zwei Schlüsselelemente machen ein Modell zur Glass/ White Box: Die verwendeten Features müssen für Menschen verständlich sein, und der maschinelle Lernprozess selbst muss transparent dokumentiert sein. Das umfasst unter anderen nachvollziehbare Trainingsdaten, klare Modellarchitektur, offene Parameter und ein überprüfbares Optimierungsverfahren.
- Explainable AI = "Black Box mit Fenstern"
Im Kopf der KI - Wie Forscher:innen dem Denken der KI auf der Spur sind
Bei großen Sprachmodellen wie GPT oder Claude versuchen Forscher:innen mit mechanistischer Interpretierbarkeit, die internen Abläufe zu kartografieren: Wie speichern neuronale Netze Wissen? Wie entstehen emergente Konzepte wie "Eiffelturm" oder "Ironie"?
Bei Anthropic etwa nutzt man Autoencoder, um in Claude 3 "Neuronengruppen" bestimmten Konzepten zuzuordnen: z. B. das "Golden Gate Bridge"-Neuron oder das "Neuroscience"-Cluster. Ziel: Die Landkarte des KI-Denkens zu erstellen. (Einblick: Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet)
Ein verwandter Ansatz ist "Chain of Thought Reasoning" - hier soll die KI Schritt für Schritt ihre Argumentation offenlegen. Das Ziel: Modelle, die nicht einfach ein Ergebnis ausspucken, sondern dabei zeigen, wie sie zu ihrer Schlussfolgerung gekommen sind - etwa indem sie bei Rechenaufgaben oder logischen Problemen eine gedankliche Zwischenschritt-Kette darstellen.
OpenAI hat diesen Ansatz in einer aktuellen Veröffentlichung vertieft: Große Sprachmodelle wie GPT-4 können durch gezieltes Prompting und Training dazu gebracht werden, eine Art 'Gedankenkette' aufzubauen - also ihren inneren Entscheidungsprozess nachvollziehbar zu machen. Das verändert nicht nur die Art, wie wir mit Modellen interagieren, sondern auch, wie wir Vertrauen zu ihnen entwickeln können.
Erste Implementierungen zeigen, dass die Leistung bei komplexen Aufgaben steigt, wenn die Modelle explizit zum Nachdenken angeleitet werden. In der Praxis bedeutet das: Statt nur die richtige Antwort zu liefern, schreibt die KI ihre Überlegung wie ein Protokoll mit.
Warum wir erklärbare KI brauchen
Eine vertrauenswürdige und verantwortungsvolle KI-Entwicklung braucht mehr als Rechenleistung und Output. Sie braucht Verständlichkeit als Prinzip. Denn:
- Nur transparente Systeme ermöglichen es, gesellschaftliche und rechtliche Normen wie Fairness und Diskriminierungsfreiheit systematisch zu integrieren.
- Nur nachvollziehbare Entscheidungen schaffen die Grundlage für rechtsstaatliche Kontrolle.
- Nur verständlich aufgebaute KI-Systeme können dort eingesetzt werden, wo es um Leben, Rechte oder Existenzen geht: in der medizinischen Diagnose, bei Kreditentscheidungen, im Strafvollzug oder im autonomen Verkehr.
Zusammengefasst: Ohne "Interpretability by Design" bleibt Vertrauen ein leeres Versprechen.
Anforderungen an Erklärbarkeit im EU AI Act
Der EU AI Act verpflichtet Anbieter hochriskanter KI-Systeme - etwa in Justiz, Strafverfolgung oder Kreditvergabe - zur Erklärbarkeit (Art. 13 AI Act). Nutzer:innen und Behörden müssen die Logik, Bedeutung und Funktionsweise der Systeme nachvollziehen und die Ergebnisse des Systems interpretieren und angemessen nutzen können. Damit wird Erklärbarkeit zur rechtsverbindlichen Anforderung
Schlussfolgerung: Ohne Transparenz kein Vertrauen – und keine Kontrolle
Erklärbarkeit ist kein technisches Nice-to-have, sondern ein verfassungsrechtlich motiviertes Muss. In einem System, das auf Nachvollziehbarkeit und Begründungspflicht baut, kann sich KI nicht hinter Intransparenz verstecken. Der EU AI Act macht deutlich: Wer KI einsetzt, muss erklären können – verständlich, überprüfbar und für Betroffene greifbar.
Auch am Beispiel Strafrecht zeigt sich, wie gefährlich Black Box-Systeme sein können – etwa wenn algorithmische Risikobewertungen richterliche Entscheidungen beeinflussen, ohne dass Verteidigung oder Gericht die Berechnungslogik prüfen können. Welche Konsequenzen das für die Unschuldsvermutung, das Prinzip der Unmittelbarkeit und das faire Verfahren hat, analysiere ich im Blogbeitrag „In dubio pro Algorithmus?“. Denn ein System, das über Schuld entscheidet, darf keine Rätsel offen lassen.
Erklärbarkeit ist der Schlüssel zu gerechter KI – für Entwickler:innen, Gerichte, Verwaltung und vor allem: für die Menschen, die davon betroffen sind. Ohne Transparenz verlieren wir nicht nur Vertrauen, sondern auch Kontrolle.
„Don’t be evil“ reicht nicht mehr. Heute heißt es: Be explainable. Und morgen? Vielleicht sogar: Be accountable.
Quellen:
Learning to reason with LLMs | OpenAI
What Is Black Box AI and How Does It Work? | IBM
We Now Know How AI ‘Thinks’—and It’s Barely Thinking at All - WSJ
What is White Box (Glass Box) vs. Black Box AI?
AI Black Box Problem: Can We Break the Code on AI’s Logic? · Neil Sahota
The AI Black Box: What We’re Still Getting Wrong about Trusting Machine Learning Models - Hyperight